Berlins Open Data Network
Eine Clusteranalyse zeigt, zu welchen Themen die meisten Daten im Open Data Portal Berlin vorhanden sind und wie sie sich durch Tags miteinander verknüpfen lassen
Hintergrund und Zielsetzung
Offene, frei-verfügbare Datensätze werden für das Land Berlin zentral über eine Plattform gesammelt, dem Open Data Portal Berlin. Wer offene Daten sucht, für den ist diese Website die erste Anlaufstelle. Damit spezielle Datensätze von Nutzer*innen in der Fülle des Portals auch gut gefunden werden können, wird jeder Datensatz durch Schlüsselworte, die sogenannten Tags, beschrieben. Diese Tags werden verwendet, um den Inhalt jedes Datensatzes schnell erfassbar zu machen und ermöglichen den Nutzer*innen so, andere Datensätze zu ähnlichen Themen zu finden. Zum Beispiel wird der Datensatz zu eMobility-Elektrostationen durch Tags wie Elektro-Ladesäulen, Mobilität und Emobility beschrieben, die wiederum jeweils mit anderen Daten verknüpft sind. Im Durchschnitt wird jeder Datensatz durch 11,7 Tags beschrieben.
Unser Ziel war es festzustellen, welche Tags am häufigsten mit welchen anderen Tags vorkommen, um ein thematisches Netzwerk für alle auf dem Berlin Open Data Portal verfügbaren Datensätze zu skizzieren. So lässt sich nachvollziehen, welche Tags themenübergreifend Relevanz haben und welche Themen typischerweise inhaltlich am nächsten beieinander liegen. Die Daten, die für diese Analyse verwendet wurden, sind die Tags von allen 2643 Datensätzen, die auf dem Berlin Open Data Portal zu diesem Zeitpunkt (15. März 2021) verfügbar waren.
Datengrundlage und Extraktion der Tags
Das Datenregister, das für die Eingabe und Speicherung aller Datensätze im Berlin Open Data Portal verwendet wird, basiert auf der weit verbreiteten Software CKAN (Comprehensive Knowledge Archive Network). CKAN bietet eine sogenannte API, d.h. eine Schnittstelle zur Programmierung von Anwendungen. Damit ist es möglich, eine über die Funktionen der Weboberfläche des Datenportals hinausgehende Suche oder Analyse der Portalinhalten durchzuführen. Mehr Informationen über CKAN im Zusammenhang mit dem Datenportal sind hier zu finden.
Um an die Daten zu den Tags der einzelnen Datensätze zu kommen, haben wir die CKAN-API verwendet. Mit Hilfe der Programmiersprache R und des R-Pakets ckanr haben wir eine Abfrage erstellt, um auf die Metadaten aller Datensätze des Open Data Portals zuzugreifen. Die Ausgabe dieser Abfrage ist ein JSON-Objekt, das als Tabelle dargestellt werden kann, wobei jede Zeile Informationen über einen Datasatz des Open Data Portals enthält. Eine der Spalten in dieser Tabelle enthält eine Liste aller Tags, die für den jeweiligen Datensatz vermerkt sind - genau die Informationen, die wir für dieses Projekt benötigten.
In einem nächsten Schritt wurden die Tags getrennt und bereinigt, um Duplikate zu vermeiden. Dafür haben wir die Tags vereinheitlicht, indem wir Wörter mit Singular- oder Pluralformen desselben Substantivs, mit oder ohne Akzenten und mit oder ohne Großbuchstaben jeweils auf eine Form reduziert haben. Zusätzlich haben wir Stoppwörter wie der oder ein entfernt, die für unsere Analyse überflüssig sind und vom Inhalt der Tags ablenken. Nach diesen Änderungen entfernten wir außerdem den Tag Berlin, der der am häufigsten verwendete Tag im Datenportal ist - ohne dabei relevante Informationen zu liefern.
Analyse der Tags
Die Tag-Zusammenhänge wurden nun analysiert, indem wir Bigramme aus allen gemeinsam vorkommenden Tags erstellten. So konnten wir identifizieren, welche Tags mit welchen anderen Tags für die selben Datensätze verwendet wurden und wie häufig. Daraus ergaben sich 22.783 Tag-Bigramme, deren Häufigkeitsverteilung im folgenden Graphen dargestellt ist.
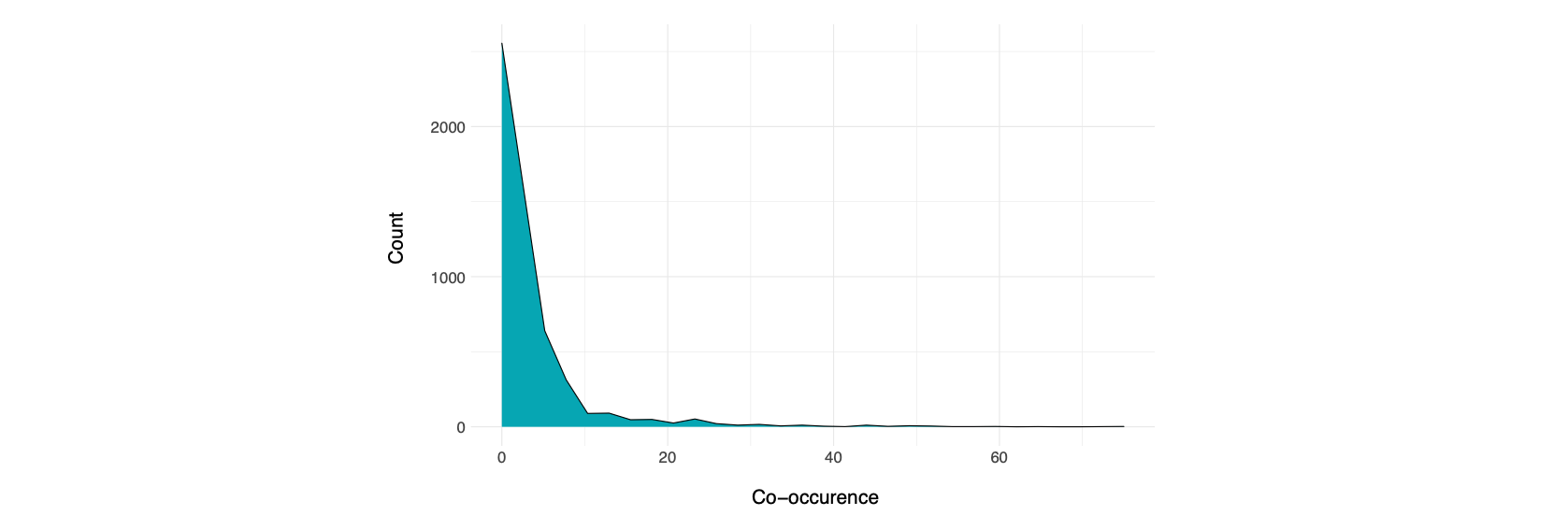
Von diesen 22.783 Tags haben wir als Teilmenge für die weitere Analyse die 342 am häufigsten vorkommenden Bigramme und somit insgesamt 138 Tags extrahiert. In dieser Teilmenge liegt der Median des Tag-Vorkommens bei 13,5 (für den gesamten Datensatz liegt der Median bei 2), was bedeutet, dass Tag-Pärchen statistisch gesehen am häufigsten in 13-14 verschiedenen Datensätzen auftreten (wie z.B. bei Kinder und Migrationshintergrund). Es geht aber auch deutlich häufiger. Die Pärchen mit den höchsten Vorkommen sind in bis zu 183 Datensätzen zu finden (z.B. Geodaten und Karten).
Im nächsten Schritt wurde eine automatische Clusteranalyse aller Tags auf der Grundlage der Bigramme durchgeführt. Mithilfe eines Louvain-Community-Detection-Modells konnten wir identifizieren, wie häufig Bigramme mit welchen anderen Bigrammen vorkommen und so ein Netzwerk von Tag-Verbindungen erstellen. Unter Verwendung der am häufigsten verwendeten Tags identifizierten wir mit dieser Clusteranalyse 13 verschiedene Kategorien, die ein oder mehrere Bigramme enthalten. Das Detection-Modell ist zwar hilfreich, um aufzuzeigen welche Bigramme mit welchen anderen Bigrammen auftreten, aber die Software selbst ist nicht in der Lage, das zugrunde liegende Konzept zu verstehen das z.B. Begriffe wie Preise und Werte vereint. Wir haben daher manuell Labels für die Kategorien vergeben, indem wir unser Verständnis des gemeinsamsten konzeptionellen Nenners hinter diesen Gruppen von Tags verwendet haben.
Visualisierung
Anhand der Informationen aus unserer Datenanalyse haben wir mit der Funktion visNetwork in R eine Netzwerkvisualisierung der Tags unseres Datensatzes erstellt. Diese Visualisierung enthält eine Suchoption für Tags und Kategorien. Die Knotenpunkte, von denen jeder einen anderen Tag repräsentiert, werden gewichtet, um die Anzahl ihrer gesamten Vorkommen über alle Datensätze hinweg darzustellen - je größer der Node, desto häufiger kommt der zugehörige Tag im Berlin Open Data Portal vor. Die Kanten bzw. Linien, die diese Knoten miteinander verbinden, zeigen an, wie oft die Tags gemeinsam in Datensätzen vorkommen, also wie viele Tag-Pärchen durch die Bigramm-Analyse gefunden wurden. Der Graph ist interaktiv: Wenn man auf einen der Knoten oder Kanten klickt erscheinen die zugehörigen Tags, sowie deren Kategorie und Vorkommenshäufigkeiten.
Zusammenfassend lässt sich sagen, dass unsere Taganalyse einen interessanten Einblick in die Vielfalt, Häufigkeit und Zusammenhänge der durch die Datensätze abgedeckten Themen gibt. Tags sind und bleiben ein wichtiges Tool, um Daten zu beschreiben und besser auffindbar zu machen. Natürlich kann der Graph aber nicht alle Zusammenhänge darstellen, da nur die häufigsten Tags bzw. Verbindungen mit eingeflossen sind.